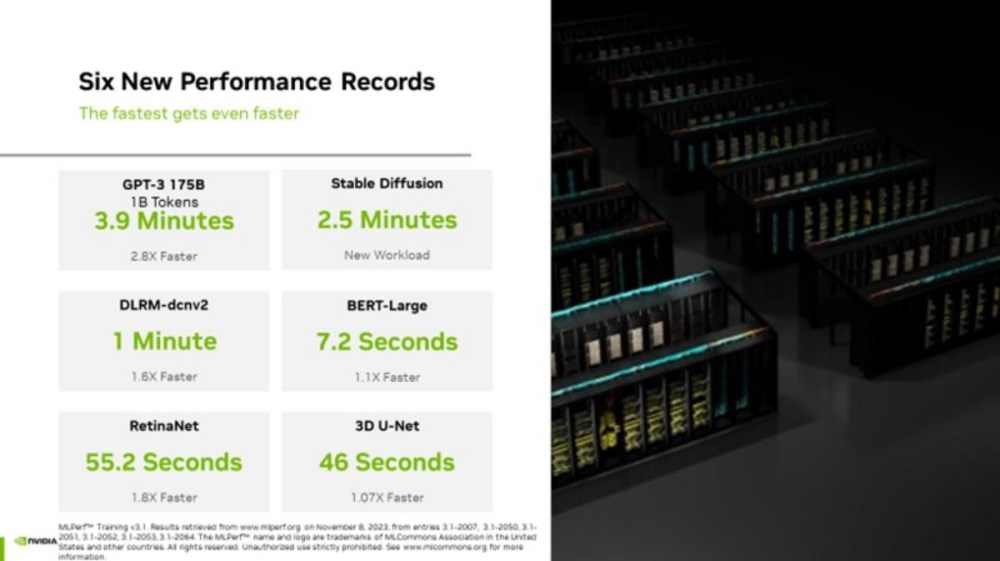
采用H100 Tensor Core GPU的NVIDIA EOS超级电脑完成GPT-3训练的效率是先前纪录的三倍,展现了在大型AI应用场景下的强大潜力。
NVIDIA表示,去年宣布推出的H100 Tensor Core GPU再次於MLPerf基准测试创下新纪录,相比近半年前的纪录快上3倍。
此次以10752组H100 Tensor Core GPU与Quantum-2 InfiniBand网路技术构成的NVIDIA EOS人工智慧超级电脑,在短短3.9分钟内完成以Open AI GPT-3大型自然语言模型、多达1750亿组参数的训练基准,相比近半年前以10.9分钟完成的纪录,约快上3倍速度。
而从此训练基准仅采用GPT-3资料集的一部分,若要完成所有训练的话,大制约花费8天时间,仍比过往透过512组A100 GPU的超级电脑约仍上73倍。

NVIDIA表示,在GPU数量增加3倍情况下,训练效率也相对提高2.8倍,而更有部分得力於软体最佳化,使得训练效率可提升达93%。而缩短训练所需时间,更意味将使人工智慧成长速度可大幅提升。
在此次测试中,NVIDIA表示在训练推荐模型运算表现也比先前快上1.6倍,在电脑视觉模型RetinaNet上的运作效率更提高1.8倍,同时也强调H100 GPU在MLPerf九项测试均有最高效能及最大运算扩展能力,更意味能使需要训练大量大型自然语言模型,或是使用NVIDIA NeMO等框架的人工智慧服务能更快进入市场,甚至能以更低训练成本与更少能源损耗运作。

从2018年5月推出以来,MLPerf基准测试藉由本身客观、透明特性,已经获得亚马逊、Arm、百度、Google、哈佛大学、HPE、Intel、联想、Meta、微软、史丹佛大学与多伦多大学在内机构采纳使用,同时也成为NVIDIA用於衡量其超级电脑、加速运算元件效能衡量基准。

{kind=link}